 HuMachine
HuMachine
The future will probably be awesome, but at present, artificial intelligence (AI) poses some questions, and most often they have to do with morality and ethics. How has machine learning already surprised us? Can you trick a machine, and if so, how difficult is it? And will it all end up with Skynet and rise of the machines? Let’s take a look.
Strong and weak artificial intelligence
First, we need to differentiate between two concepts: strong and weak AI. Strong AI is a hypothetical machine that’s able to think and is aware of its own existence. It can solve not only tailored tasks, but also learn new things.
Weak AI already exists. It is in applications made to solve specific problems, such as image recognition, car driving, playing Go, and so on. Weak AI is the thing we call “machine learning.”
We don’t know yet whether strong AI can be invented. According to expert surveys, we’ll have to wait another 45 years. That really means “someday.” For example, experts also say fusion power will be commercialized in 40 years — which is exactly what they said 50 years ago.
What could go wrong?
It’s still unclear when strong AI will be developed, but weak AI is already here, working hard in many areas. The number of those areas grows every year. Machine learning lets us handle practical tasks without obvious programming; it learns from examples. For more details, see “How machine learning works, simplified.”
We teach machines to solve concrete problems, so the resulting mathematical model — what we call a “learning” algorithm — can’t suddenly develop a hankering to defeat (or save) humanity. In other words, we shouldn’t be afraid of a Skynet situation from weak AI. But some things could still go wrong.
1. Bad intentions
If we teach an army of drones to kill people using machine learning, can the results be ethical?
A small scandal broke last year surrounding this very topic. Google is developing software used for a military project called Project Maven that involves drones. In the future, it may help create completely autonomous weapon systems.
As a result, 12 Google employees resigned in protest and 4,000 more signed a petition requesting the company abandon the contract with the military. More than 1,000 well-known scientists in the fields of AI, ethics, and IT wrote an open letter to Google, asking the company to abandon the project and support an international agreement that would ban autonomous weapons.
2. Developer bias
Even if machine-learning algorithm developers mean no harm, a lot of them still want to make money — which is to say, their algorithms are created to benefit the developers, not necessarily for the good of society. Some medical algorithms might recommend expensive treatments over the treatments with the best patient outcomes, for example.
Sometimes society itself has no interest in an algorithm becoming a moral paragon. For example, there is a compromise between traffic speed and the car accident death rate. We could program autonomous cars to drive no faster than 15 mph, which would almost guarantee to bring the number of road fatalities to zero but negate other benefits of using a car.
3. System parameters not always include ethics
Computers by default don’t know anything about ethics. An algorithm can put together a national budget with the goal of “maximizing GDP/labor productivity/life expectancy,” but without ethical limitations programmed into the model, it might eliminate budgets for schools, hospices, and the environment, because they don’t directly increase the GDP.
With a broader goal, it might decide to increase productivity by getting rid of anyone who is unable to work.
The point is, ethical issues must be incorporated from the very beginning.
4. Ethical relativity
Ethics change over time, and sometimes quickly. For example, opinions on such issues as LGBT rights and interracial or intercaste marriage can change significantly within a generation.
Ethics can also vary between groups within the same country, never mind in different countries. For example, in China, using face recognition for mass surveillance has become the norm. Other countries may view this issue differently, and the decision may depend on the situation.
The political climate matters, too. For example, the war on terrorism has significantly — and incredibly quickly — changed some ethical norms and ideals in many countries.
5. Machine learning changes humans
Machine-learning systems — just one example of AI that affects people directly — recommend new movies to you based on your ratings of other films and after comparing your preferences with those of other users. Some systems are getting pretty good at it.
A movie-recommendation system changes your preferences over time and narrows them down. Without it, you’d occasionally face the horror of watching bad movies and movies of unwanted genres. Using the AI, every movie hits the spot. In the end, you stop investigating and just consume what is fed to you.
It’s also interesting that we don’t even notice how we get manipulated by algorithms. The movie example is not that scary, but consider news and propaganda.
6. False correlations
A false correlation occurs when things completely independent of each other exhibit a very similar behavior, which may create the illusion they are somehow connected. For example, did you know that margarine consumption in the US correlates strongly on the divorce rate in Maine?
Of course, real people, relying on their personal experience and human intelligence, will instantly recognize that any direct connection between the two is extremely unlikely. A mathematical model can’t possess such knowledge — it simply learns and generalizes data.
A well-known example is a program that sorted patients by how urgently they required medical help and concluded that asthma patients who had pneumonia didn’t need help as badly as pneumonia patients without asthma. The program looked at the data and concluded that asthma patients were in less danger of dying and therefore should not be a priority. In fact, their death rates were so low because they always received urgent help at medical facilities because of the high risks inherent to their condition.
7. Feedback loops
Feedback loops are even worse than false correlations. A feedback loop is a situation where an algorithm’s decisions affect reality, which in turn convinces the algorithm that its conclusion is correct.
For example, a crime-prevention program in California suggested that police should send more officers to African-American neighborhoods based on the crime rate — the number of recorded crimes. But more police cars in a neighborhood led to local residents reporting crimes more frequently (someone was right there to report them to), which led to officers writing up more protocols and reports, which resulted in a higher crime rate — which meant more officers had to be sent to the area.
8. “Contaminated” or “poisoned” reference data
The results of algorithm learning depend largely on reference data, which form the basis of learning. The data may turn out to be bad and distorted, however, by accident or through someone’s malicious intent (in the latter case, it’s usually called “poisoning”).
Here is an example of unintended problems with reference data. If the data used as a training sample for a hiring algorithm has been obtained from a company with racist hiring practices, the algorithm will also be racist.
Microsoft once taught a chatbot to communicate on Twitter by letting anyone chat with it. They had to pull the plug on the project in less than 24 hours because kind Internet users quickly taught the bot to swear and recite Mein Kampf.
https://twitter.com/geraldmellor/status/712880710328139776
Here is an example of machine learning data being poisoned. A mathematical model at a computer virus analysis lab processes an average of 1 million files per day, both clean and harmful. The threat landscape keeps changing, so model changes are delivered to products installed on the clients’ side in the form of antivirus database updates.
A hacker can keep generating malicious files, very similar to clean ones, and send them to the lab. That action gradually erases the line between clean and harmful files, degrading the model and perhaps eventually triggering a false positive.
This is why Kaspersky Lab has a multilayered security model and does not rely exclusively on machine learning. Real people — antivirus experts — always monitor what the machine is doing.
9. Trickery
Even a well-functioning mathematical model — one that relies on good data — can still be tricked, if one knows how it works. For example, a group of researchers figured out how to trick a facial-recognition algorithm using special glasses that would introduce minimal distortions into the image and thus completely alter the result.

Wearing glasses with specially colored rims, researchers tricked a facial recognition algorithm into thinking they were someone else
Even in situations that don’t appear to involve anything complicated, a machine can easily be tricked using methods unknown to a layperson.

The first three signs are recognized as 45 km/h speed limit signs and the last one as a STOP sign
Moreover, to bring down a machine-learning mathematical model, the changes don’t have to be significant — minimal changes, indiscernible to human eye will suffice.
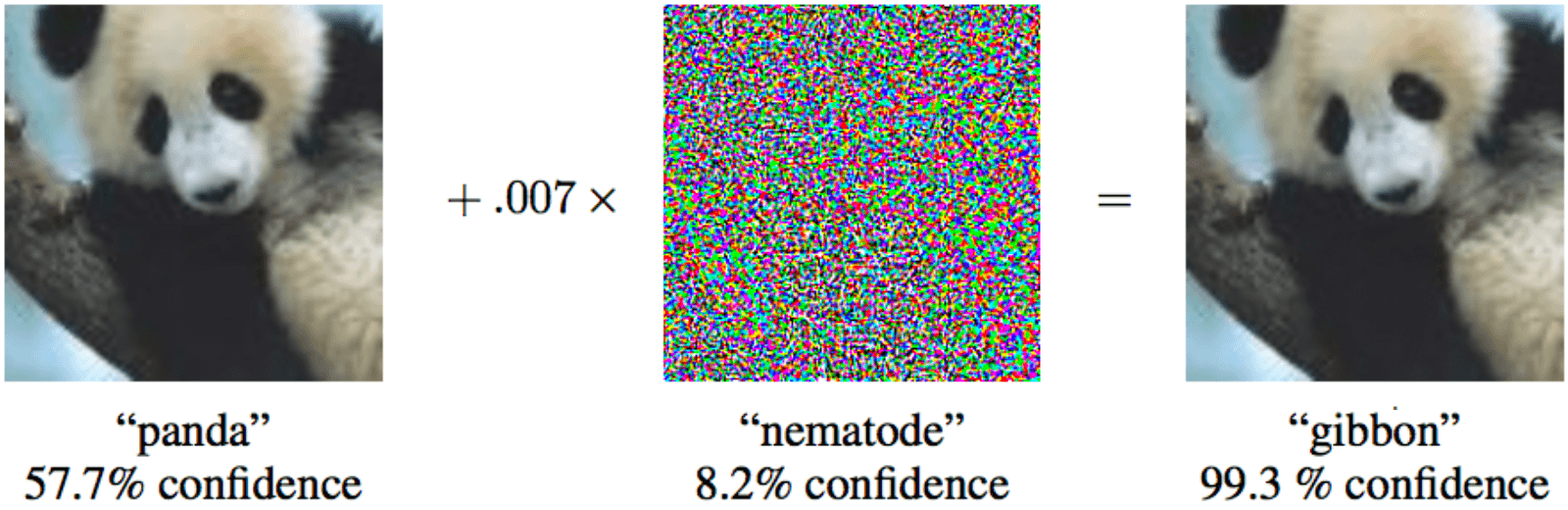
Add minor noise to the panda on the left and you might get a gibbon
As long as humanity is still smarter than most algorithms, humans will be able to trick them. Consider near-future machine learning that analyzes luggage X-rays at the airport and looks for weapons. A smart terrorist will be able to put an object of a certain shape next to a gun and thus make the gun invisible.
Who to blame and what to do
In 2016, the Obama administration’s Big Data Working Group released a report that warned about “the potential of encoding discrimination in automated decisions”. The report also contained an appeal for creating algorithms that follow equal opportunity principles by design.
Easier said than done.
First, machine-learning mathematical models are difficult to test and fix. We evaluate regular programs step-by-step and know how to test them, but with machine learning, everything depends on the size of the learning sample, and it can’t be infinite.
For example, the Google Photo app used to recognize and tag black people as gorillas. Seriously! As you can imagine, there was a scandal and Google promised to fix the algorithm. However after three years, Google failed to come up with anything better than prohibiting tagging of any objects in pictures as gorillas, chimps, or monkeys to avoid the same error.
Second, it’s hard to understand and explain machine-learning algorithms’ decisions. A neural network arranges weighted coefficients within itself to arrive at correct answers — but how? And what can be done to change the answer?
Research from 2015 showed that women see Google AdSense ads for high-paying jobs much less frequently than men do. Amazon’s same-day delivery service is often unavailable in African-American neighborhoods. In both cases, company representatives were unable to explain these decisions, which were made by their algorithms.
No one’s to blame, so we have to adopt new laws and postulate ethical laws for robotics. In May 2018, Germany took its first step in this direction and released ethical rules for self-driving cars. Among other things, it covers the following:
- Human safety is the highest priority compared with damage to animals or property.
- In the event an accident is unavoidable, there must be no discrimination; distinguishing factors are impermissible.
But what is especially important for us is that
- Automatic driving systems will become an ethical imperative, if they cause fewer accidents than human drivers.
It is clear that we will come to rely on machine learning more and more, simply because it will manage many tasks better than people can. So it is important to keep these flaws and possible problems in mind, try to anticipate all possible issues at the development stage, and remember to monitor algorithms’ performance in the event something goes awry.

 Tips
Tips